SPDY Performance on Mobile Networks
SPDY is a replacement for HTTP, designed to speed up transfers of web pages, by eliminating much of the overhead associated with HTTP. SPDY supports out-of-order responses, header compression, server-side push, and other optimizations that give it an edge over HTTP when it comes to speed. SPDY is gaining a great deal of traction -- it has been implemented in Chrome, Firefox, and Amazon Silk, been deployed widely by Google, and there is now SPDY support for Apache through the mod_spdy module.
SPDY's design should help performance on mobile networks, which experience high round-trip times and typically lower throughput than to wired networks. SPDY includes several features that should improve web page download speeds on mobile networks, including:
- Header compression, which eliminates redundant data for HTTP headers;
- Out-of-order request processing, avoiding head-of-line blocking for HTTP responses;
- Use of a single TCP connection for multiple requests, eliminating overheads for TCP connection establishment (which can be high on mobile networks).
We wondered what the performance of SPDY would be compared to HTTP for popular websites, using a real phone (a Samsung Galaxy Nexus running Android), a modern, SPDY-enabled browser (Chrome for Android), and a variety of pages from real websites (77 pages across 31 popular domains).
The net result is that using SPDY results in a mean page load time improvement of 23% across these sites, compared to HTTP. This is equivalent to a speedup of 1.3x for SPDY over HTTP. Much more work can be done to improve SPDY performance on 3G and 4G cellular networks, but this is a promising start. More details below.
Methodology
Our goal was to evaluate how SPDY performs on a real browser on a real phone when fetching popular websites. The challenge was in mitigating the variability across experiments.
- Phone and browser configuration: We ran our experiments on Chrome for Android, because it has an up-to-date draft 2 implementation of SPDY and is the only mobile browser we know of that supports SPDY. We ran the browser on Android 4.0 (Ice Cream Sandwich) on a Samsung Galaxy Nexus phone. We used Chrome's remote debugging interface with a custom client that starts up the browser on the phone, clears its cache and other state, initiates a web page load, and receives the Chrome developer tools messages to determine the page load times and other performance metrics.
- Pages measured: We selected 77 URLs from a selection of 31 popular websites, to ensure a broad cross-section of both front pages and article pages across different types of sites. To ensure that the phone retrieved the same content each time it fetched a particular URL, we captured and replayed this content using the Web Page Replaytool, which eliminates the nondeterminism associated with replaying web page loads. All content was cached on our Web Page Replay server.
- Server configuration: We needed a Web server implementation that supports SPDY. The best SPDY implementation available to us is Googles internal web server, called the Google Front End (or GFE). The GFE was configured to proxy to the Web Page Replay server hosting the actual site content. The GFE and the Web Page Replay servers ran on separate Linux desktop machines on the same LAN segment. All Web page contents were stored on the Web Page Replay servers local disk to eliminate additional sources of latency. The phones' /etc/hosts file was modified to return the GFE machine's IP address for all domain lookups, essentially isolating the phone and the desktop from the Internet. As a result, our measurements do not include realistic DNS lookup times.
- Consistent network conditions: In prior experiments, we found page load times to be highly variable over real 3G and 4G cellular networks, making it hard to draw conclusions without running hundreds of experiments per site in order to estimate the statistical distribution. To reduce this variability, the phone was tethered to the desktop machine hosting the server using a USB connection, and traffic shaping was applied to the tethered connection using Dummynet. We emulated a 3G network with uplink bandwidth of 1 Mbps, downlink bandwidth of 2 Mbps, and a round-trip delay of 150 ms. These values were chosen as representative of cellular network performance in the United States. Note that packet loss was not included in the traffic shaping parameters, since cellular networks hide packet loss at the PHY layer, and our previous experiments have shown a TCP-level packet loss of less than 1% over typical cellular networks.
- Data collection: For each page load, we recorded the page load time reported by the browser, as well as the detailed trace of Chrome remote debugging messages which were used to reconstruct a load time waterfall for each page, including the time to load each individual resource on the page, as well as timings for TCP connections, DNS lookups, and redirects. In addition, tcpdump was run on the phone to capture a trace of all network packets sent and received during the web page load.
Below is a diagram of our testbed.

We ran two sets of experiments:
- SPDY: Fetch the 77 URLs through the GFE using SPDY.
- HTTP: Fetch the 77 URLs through the GFE using HTTP.
Note that SPDY will use a single SSL connection per domain, whereas HTTP will open multiple parallel connections for fetching resources from the server. The SPDY measurements presented here include the SSL connection setup overhead.
Table 1: Domains included in the Web page measurements
| bbc.co.uk | bloomberg.com | cricinfo.com |
| decor8blog.com | digg.com | droid-life.com |
| economictimes.com | espncricinfo.com | flickr.com |
| greenweddingshoes.com | huffingtonpost.com | ibtimes.com |
| imgur.com | michaeleisen.org | microsoft.com |
| nlm.nih.gov | qq.com | quickmeme.com |
| reddit.com | reuters.com | sciencemag.org |
| seattletimes.nwsource.com | slashdot.org | sohu.com |
| theboombox.com | timesofindia.com | wikipedia.org |
| windowsteamblog.com | wired.com | yomiuri.co.jp |
Results
Figure 2 shows the page load time for each of the 77 URLs using both HTTP and SPDY. As the figure shows, in all but one case, SPDY is faster than HTTP, with an average page load time reduction of 23% across all pages. For one of the URLs (an article from huffingtonpost.com), the page loaded 6% slower on SPDY than HTTP.
Figure 2: Comparison of SPDY vs. HTTP page load times
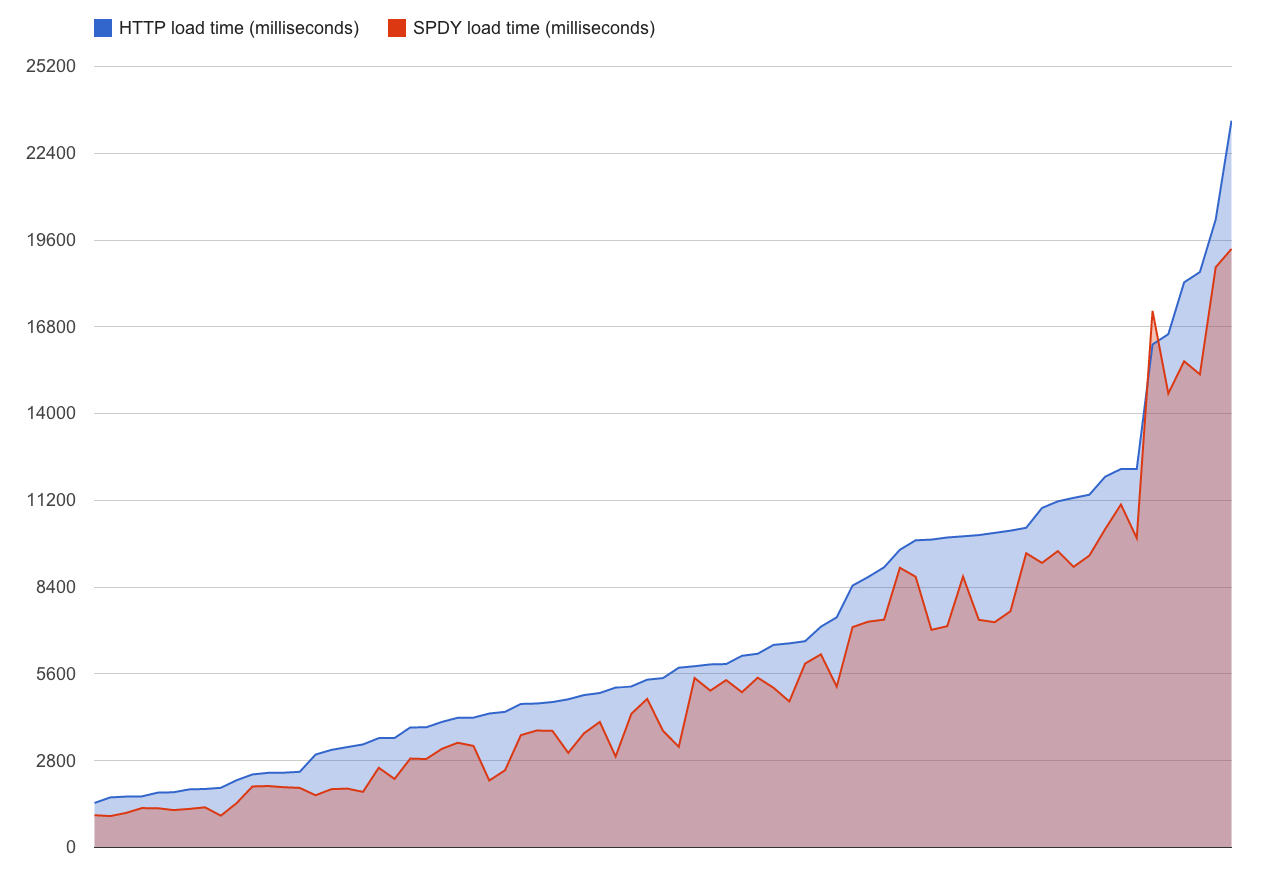
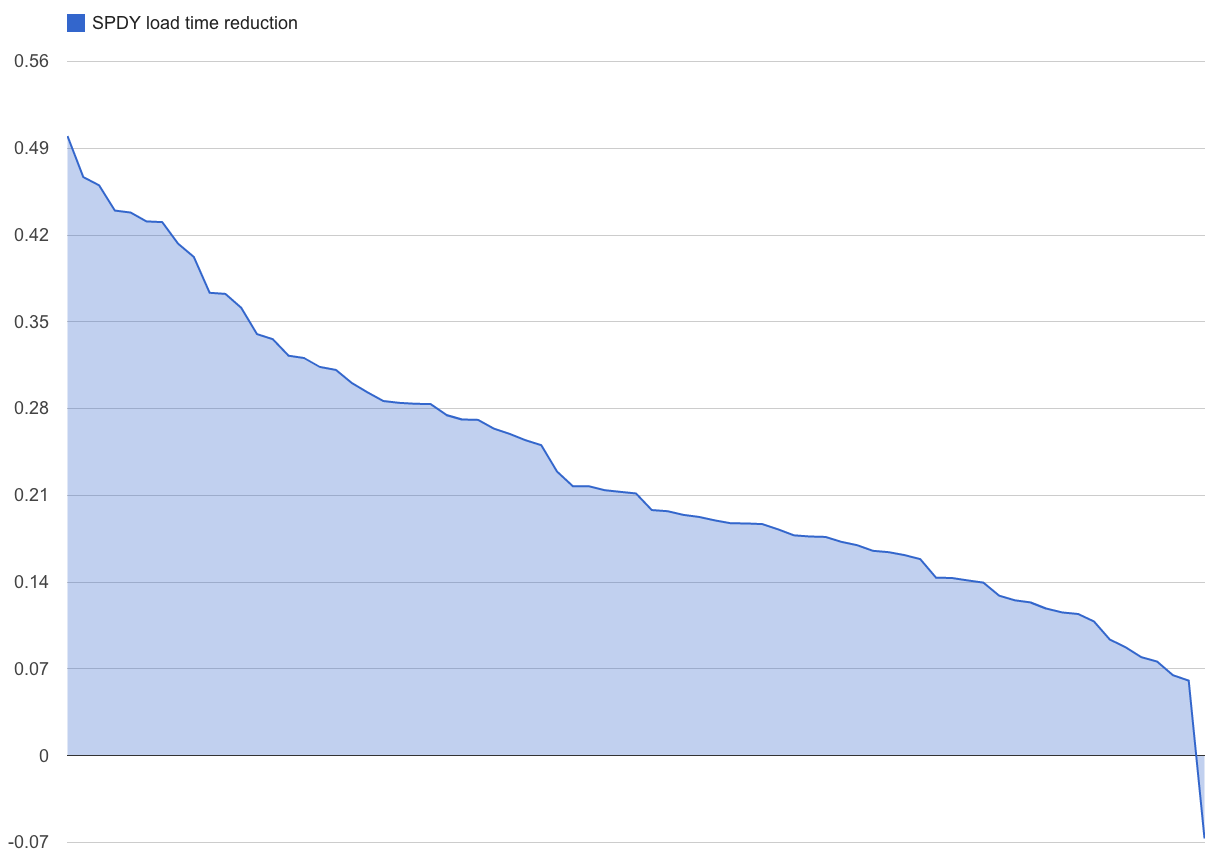
Figure 3 shows the average SPDY load time reduction for each of the measured pages. The load time reduction is calculated as (SPDY load time) / (HTTP load time) for each page.
Figure 3: Page load time reduction for SPDY for each of the measured sites
In order to take a closer look at SPDY's performance, Figures 4 and 5 show the waterfall chart for SPDY and HTTP (respectively) for one of the pages.
Figure 4: SPDY load waterfall for http://en.m.wikipedia.org/wiki/Harvard_University
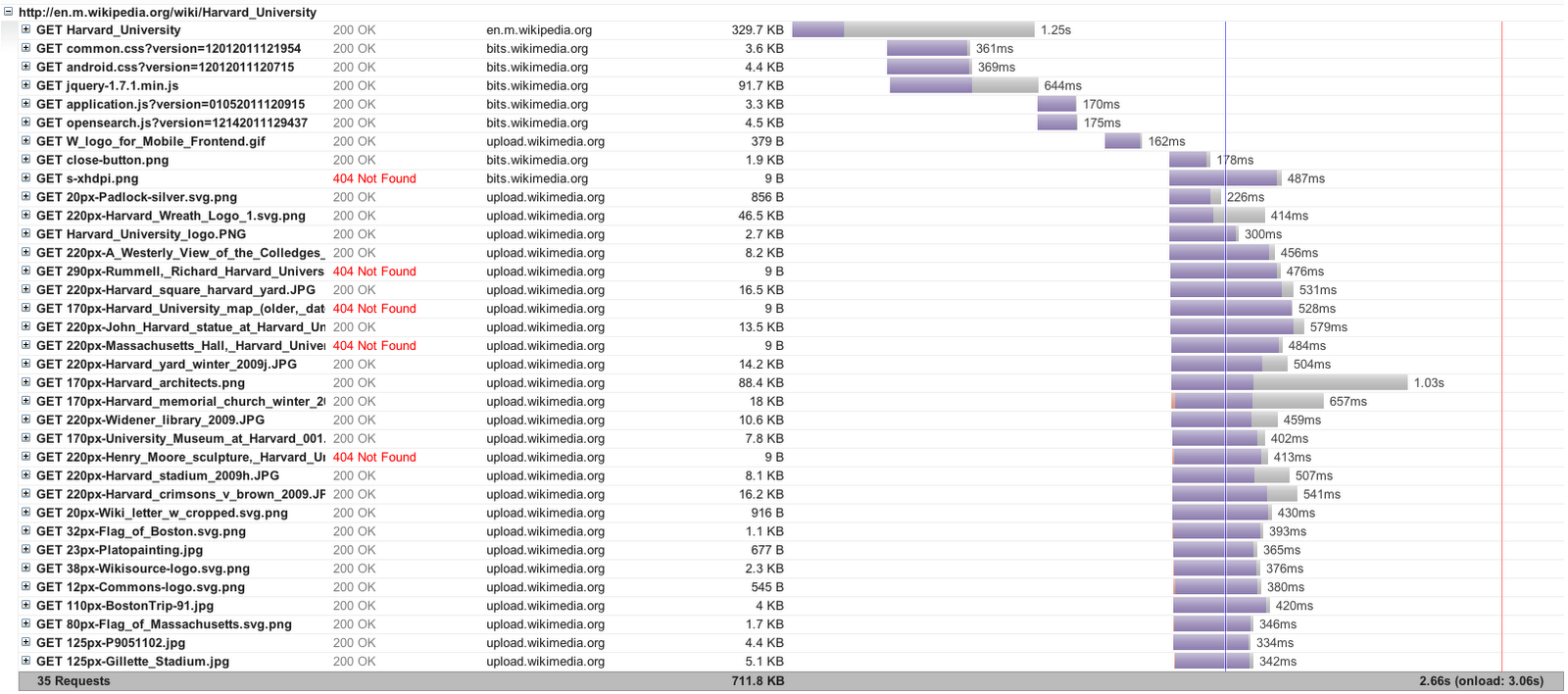
Figure 5: HTTP load waterfall for http://en.m.wikipedia.org/wiki/Harvard_University
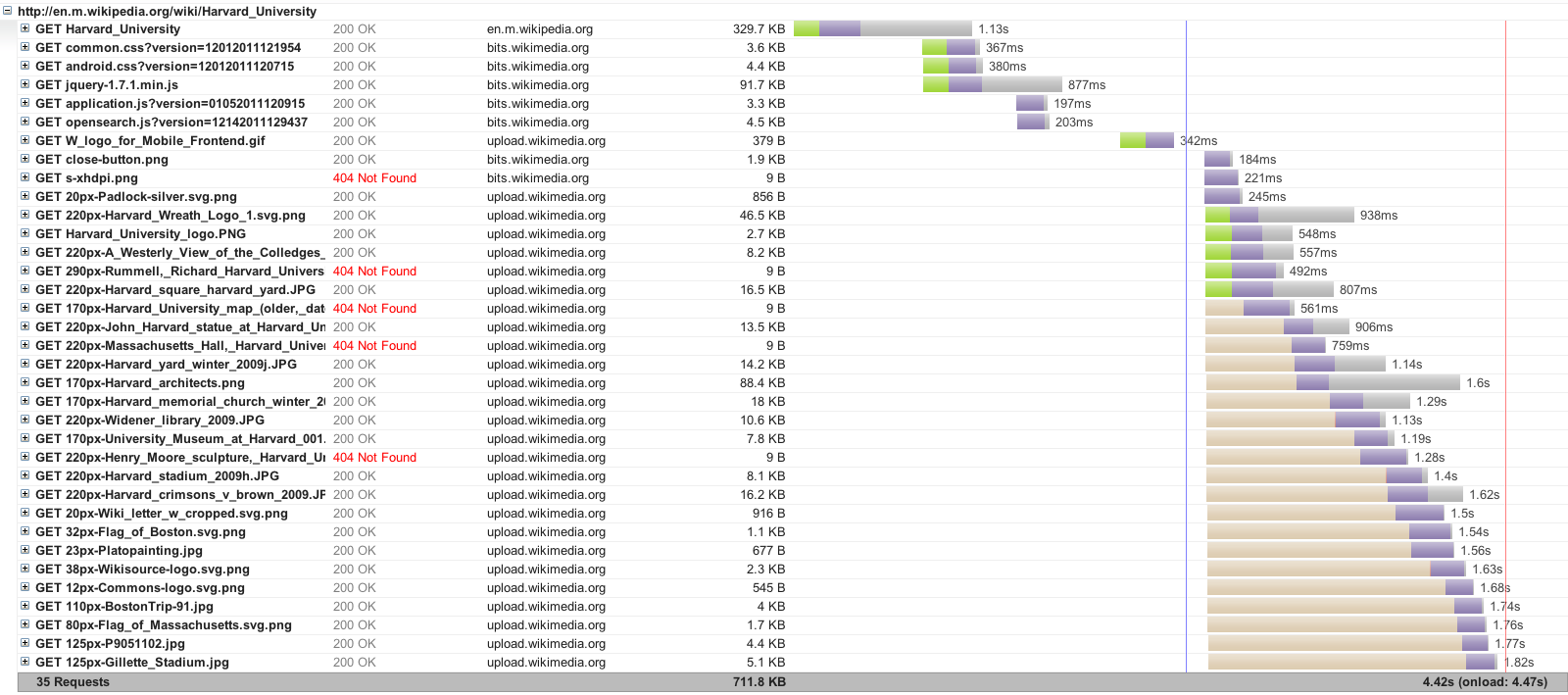
The waterfall diagrams clearly show SPDY's main advantage over HTTP: The use of out-of-order responses. In the SPDY case, the browser opens a number of SPDY streams (over the same TCP connection) to fetch the various resources on the page, whereas in HTTP, each of the resources are fetched across several (6 in this case) TCP connections, with each connection handling requests in a FIFO fashion. Note that there are several 404 Not Found errors in both traces, owing to the Web Page Replay setup not caching all of the resources on the page.
Conclusions
SPDY shows promise to improve the performance of web page load times over mobile networks. Of course, its necessary to look across many more sites and a wider range of network conditions, but in this controlled experiment we find that SPDY yields a mean page load time reduction of 23% over HTTP, yielding a speedup of 1.3x. Website operators should consider using SPDY to speed up access to their sites from mobile devices.

